Showing 1 to 15 of 2075 results


Device to reinforce the ankle and improve the footprint
Innovative Products and Technologies Universidad de Granada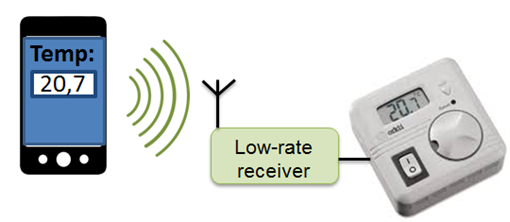

Data modulation method for Wi-Fi off-the-shelf transmitters to communicate with non-Wi-Fi IoT devices
Patents for licensing Universitat Politècnica de Catalunya - UPC

MUST - Managing Urban Spaces Together
Innovative Products and Technologies Luxembourg Institute of Science and Technology (LIST)

DRONA: Software requirements management tool for Enterprise Architect
Investment Opportunities in Startups and Spinoffs SnT
Licensing partner required a plant-derived technology
Innovative Products and Technologies National Biofilms Innovation Centre

Material Characterization
Research Services and Capabilities TEC Eurolab

Organic derivatives for the manufacture of electronic devices
Patents for licensing Consejo Superior de Investigaciones Científicas
USE OF NEW PHARMACOLOGICAL CHAPERONES FOR THE TREATMENTOF LYSOSOMAL STORAGE DISORDERS - CF4Lyso
Patents for licensing Fundación Biomedica Galicia Sur

SAXETHANE: Urethane Modified Soy Fatty Acid Ester
Knowhow and Research output Airable Research Lab, business line of Ohio Soybean Council
Compounds for the treatment and prevention of immune-mediated inflammatory diseases
Patents for licensing Consejo Superior de Investigaciones Científicas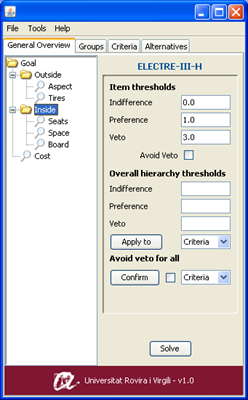

ELECTRE-H software package: a tool for data analysis and decision aiding with hierarchical criteria
Innovative Products and Technologies Fundació URV

Highly Sensitive Nanoscale Scanning Magnetic and Thermal Sensor
Patents for licensing Yeda

Blue-Tech-HDB, Solving the problem of bad odors comes from of Mercaptans, H2S and Amine.
Innovative Products and Technologies DNA CATCHER S.L.U
Sustainable concrete with wind turbine blade waste
Patents for licensing UNIVERSIDAD DE BURGOS

