Showing 1 to 15 of 2075 results


Vibration-Assisted ball burnishing
Patents for licensing Universitat Politècnica de Catalunya - UPC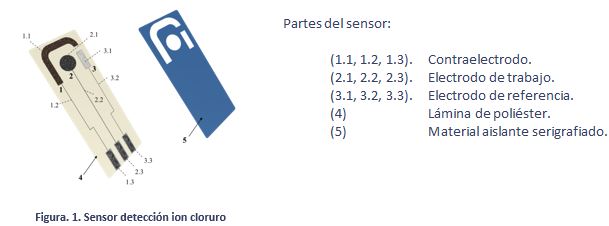

Electrochemical sensor for the “in situ” detection and measurement of chloride ion in fluid samples
Patents for licensing UNIVERSIDAD DE BURGOS

Method for predicting sex in fish
Patents for licensing CSIC - Consejo Superior de Investigaciones Científicas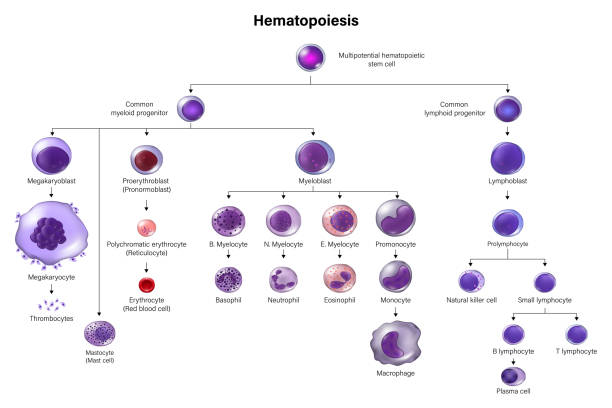

Targeting Novel Regulator for Improved Hematopoietic Stem Cells Generation
Patents for licensing Yeda

SCANTRUST - Build Brand Trust Through Supply Chain Transparency
Innovative Products and Technologies EIT Digital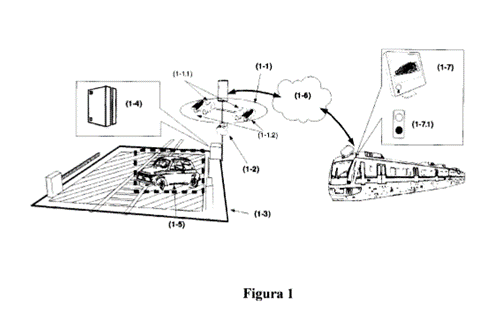

Sensor system for the detection of objects / obstacles in critical points of railway lines
Patents for licensing Universidad de Alcalá-OTRI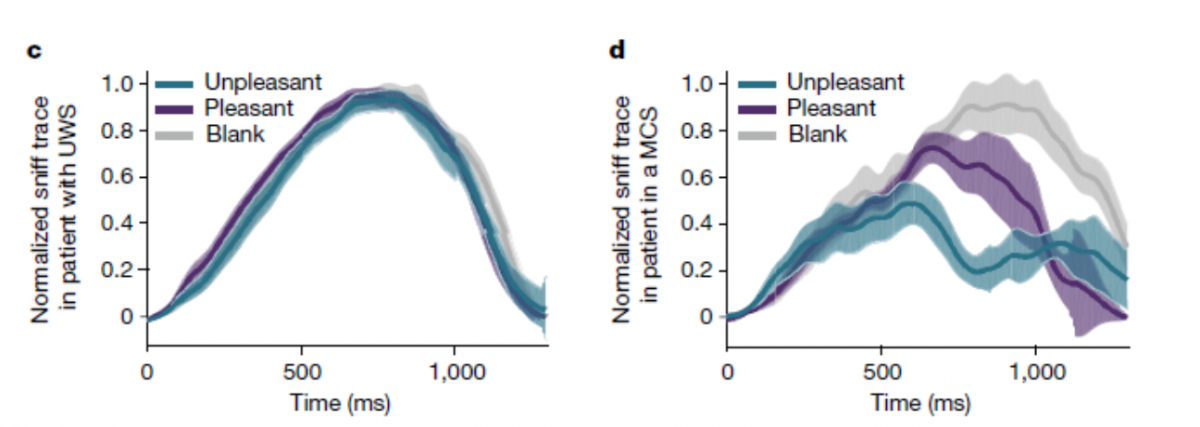
A Marker for Consciousness State Following Brain Injury
Patents for licensing Yeda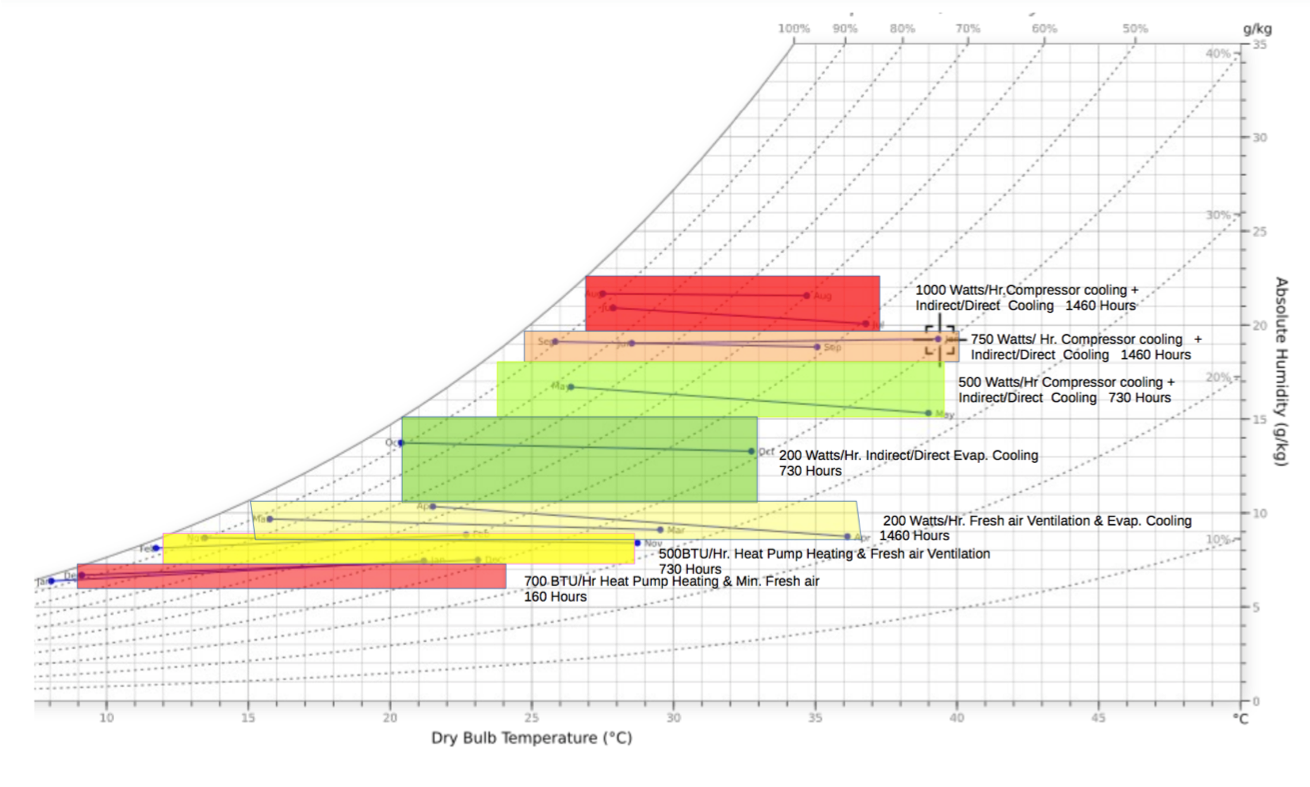

Compressor Less Air Conditioner for Arid Climate Zones
Patents for licensing TORO WATT Corp.
Fire hose element to facilitate the work of firefighters
Patents for licensing UNIVERSIDAD DE BURGOS

Neutron beam production device for cancer therapy
Patents for licensing Universidad de Granada
Service of plant in vitro culture and genetic characterization, focused on forest tree species.
Research Services and Capabilities Universidad de Alcalá-OTRI

Bioimaging Platform - Luxembourg Centre for Systems Biomedicine
Research Services and Capabilities University of Luxembourg
Vaccine for Rift Valley Fever
Patents for licensing CSIC - Consejo Superior de Investigaciones Científicas

Optical stabilization system for signal enhancement in spectrometric measurements with mechanical fluctuations
Patents for licensing Universidad de Málaga

