Showing 1 to 15 of 2075 results


Magnesium Alloys with Improved Castability
Innovative Products and Technologies Brunel University London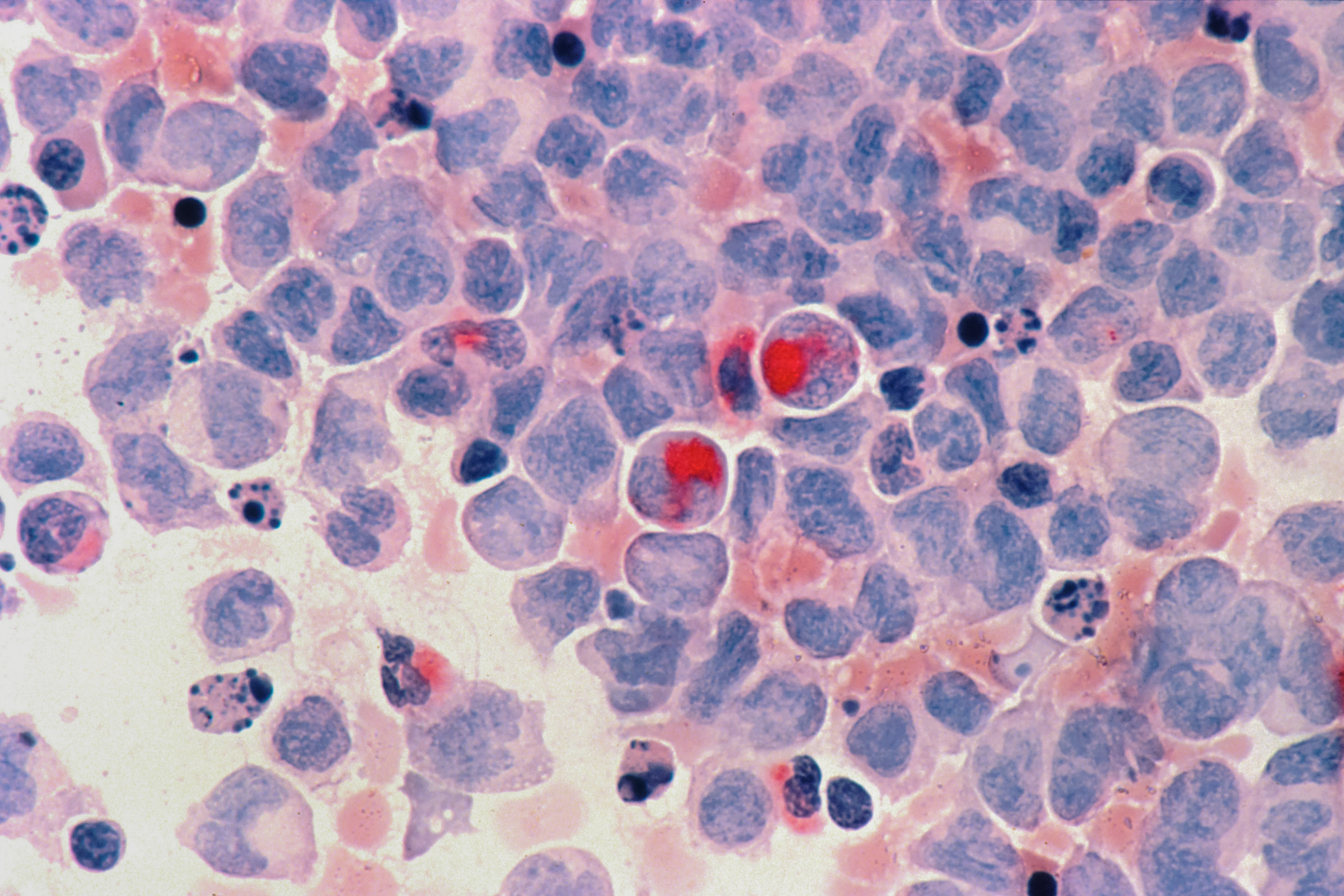

Universal CAR-Ts for Treating Cancer
Patents for licensing Yeda

GASFLOW: Supply Chain Execution System for the Gas Industry
Innovative Products and Technologies ALIZENT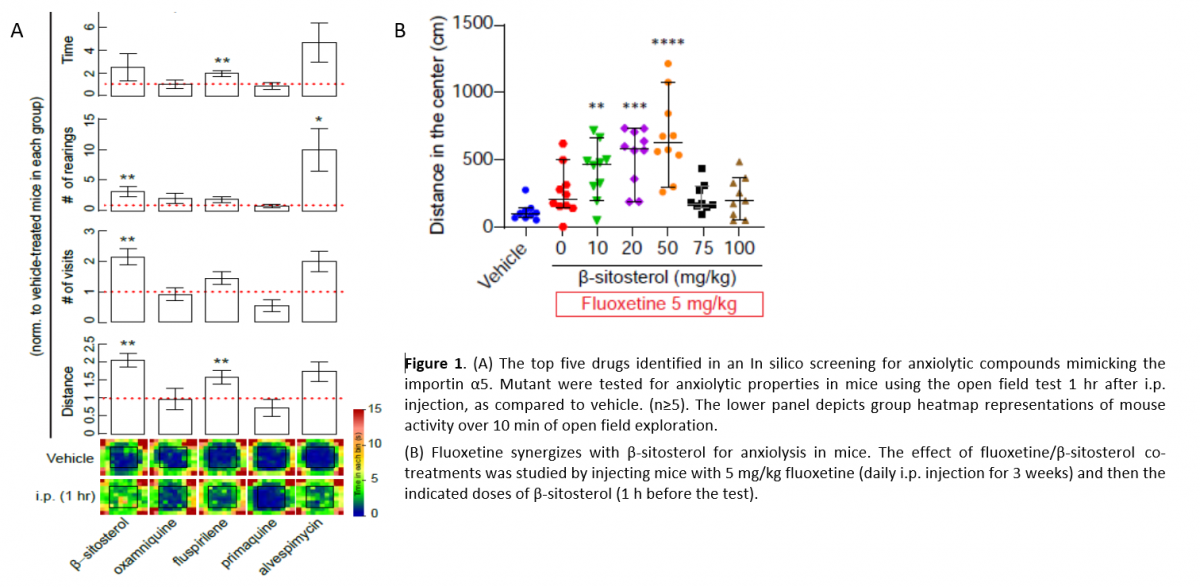
Treatment of Psychiatric Disorders by Inhibiting Importin Alpha 5
Patents for licensing Yeda

High resolution paterning in organic semiconductors
Patents for licensing Consejo Superior de Investigaciones Científicas

Vibration-assisted ball burnishing: A solution for Surface enhancement through acoustoplasticity
Innovative Products and Technologies UPC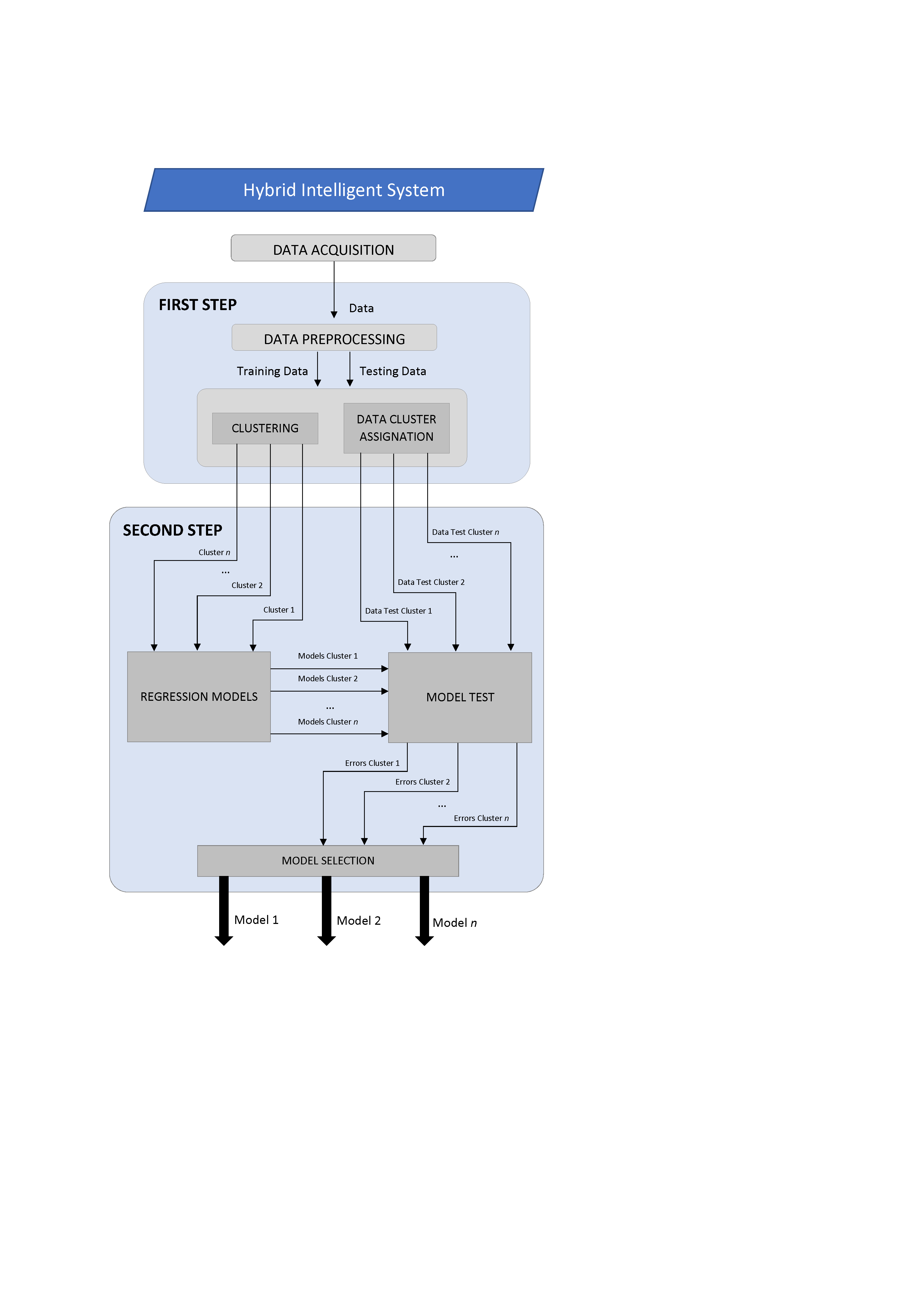

Design and deployment of Hybrid Intelligent Systems
Research Services and Capabilities UNIVERSIDAD DE BURGOS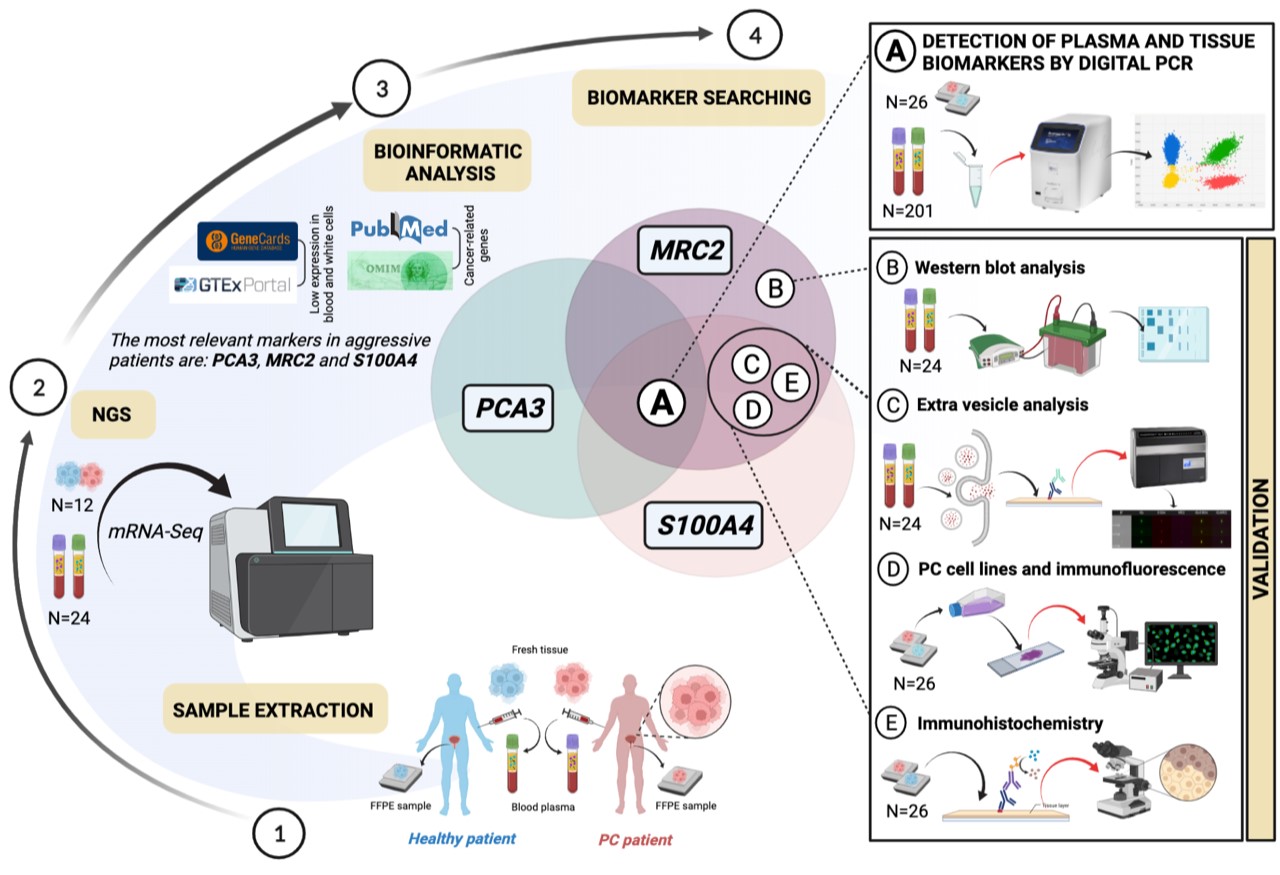

Biomarkers for non-invasive detection and classifform-control form-control ication of prostate cancer
Patents for licensing Universidad de Granada
Catalyst for nitrous oxide (N2O) decomposition
Patents for licensing Consejo Superior de Investigaciones Científicas

Embedded electronic system for the supervision of vehicles
Patents for licensing Universidad de Alcalá-OTRI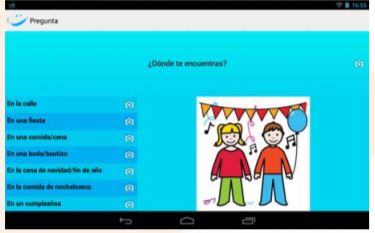
Adapting social scripts for Android platform Socio-Ruta V1.0
Patents for licensing UNIVERSIDAD DE BURGOS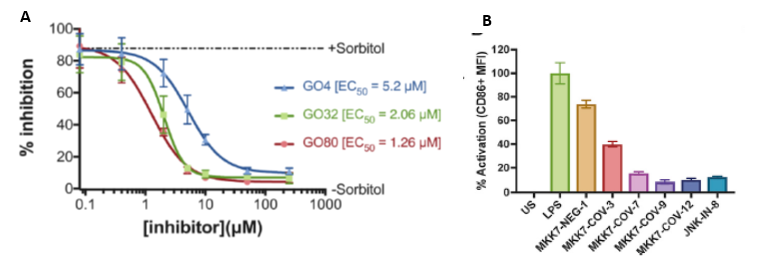
Covalent Inhibitors for Treatment of Inflammation and Neurodegeneration
Patents for licensing Yeda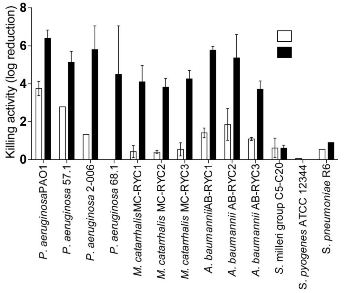
Polypeptides with antibacterial activity
Patents for licensing Consejo Superior de Investigaciones Científicas
Iron Catalyzed Ring-Opening Metathesis Polymerization (ROMP)
Patents for licensing Yeda